
























A new technical paper titled “Kitsune: Enabling Dataflow Execution on GPUs with Spatial Pipelines” was recently published by researchers at NVIDIA and the University of Wisconsin-Madison. This development addresses significant challenges in the field of deep learning (DL) as models continue to grow in size and complexity. The need for innovative solutions is paramount, particularly given that current GPU architectures may not fully leverage the potential of these advanced models.
The abstract of the paper highlights that while GPUs remain the dominant platform for DL applications, they rely on a bulk-synchronous execution model. This framework presents several limitations, especially when dealing with the heterogeneous behavior often found in modern DL models. Researchers have experimented with vertical fusion—combining multiple sequential operations into a single kernel—but this method still falls short in several key areas.
One of the main inefficiencies noted is that many resources on the GPU remain idle while only a single operator is executing, a consequence of temporal multiplexing of the Streaming Multiprocessors (SM). Additionally, the paper points out the missed opportunities for energy efficiency through intelligent on-chip data movement, which could enhance performance in environments where power provisioning is a concern. Furthermore, the current architecture struggles to exploit reduction dimensions as a source of parallelism, which can alleviate pressure on batch sizes.
To counter these challenges, the authors explore whether modest adjustments to existing GPU architectures can facilitate more efficient dataflow execution. Their proposed solution, Kitsune, introduces a set of primitives designed to construct spatial pipelines. This approach allows for dataflow execution on GPUs without the need for a complete architectural overhaul. Accompanying this is an end-to-end compiler based on PyTorch Dynamo, which integrates seamlessly into existing workflows.
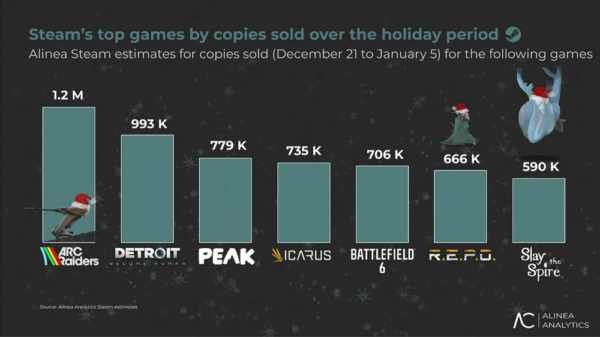
In their experiments, the Kitsune framework demonstrated impressive results across five challenge applications, achieving performance improvements of up to 2.8× for inference tasks and 2.2× for training processes. Additionally, off-chip traffic was notably reduced, with reductions of up to 99% for inference and 45% for training. These metrics underscore the potential of Kitsune to not only enhance the efficiency of model execution but also to address critical power consumption issues.
This paper represents a significant step forward in optimizing GPU performance for deep learning applications. As models become increasingly intricate, the need for more adaptable and efficient computational frameworks becomes critical. The findings from Kitsune could pave the way for further research and development in GPU architecture, potentially leading to a new generation of hardware capable of handling the demands of advanced machine learning tasks.
Moving forward, the implications of this research extend beyond mere performance metrics. As industries increasingly rely on deep learning for various applications—from natural language processing to image recognition—enhancements in GPU efficiency will be essential. The ability to execute complex models more effectively not only accelerates innovation in technology but also broadens the scope of what is achievable within the realm of artificial intelligence.
The full technical paper can be accessed at ACM Transactions on Architecture and Code Optimization, with the publication anticipated in December 2025. The authors, Michael Davies, Neal Crago, Karthikeyan Sankaralingam, and Stephen Keckler, have provided a comprehensive examination of the potential benefits of Kitsune, marking a significant milestone in the ongoing evolution of GPU technology.




















